The Data Science Accelerator Programme is an initiative run by Government Digital Service to help analysts from across the public sector to develop their data science skills.
On the course, you have 12 weeks to work on a data science solution to a business problem from your organisation. You're assigned a hub and mentors to help you tackle the problem and get the most out of your time on the programme. My assigned hub was the Office for National Statistics, but the UKHO is also a regional hub, specialising in geospatial projects.
This blog is about my project, which was officially titled 'Beach Composition Classification.' Scary, right? I like to pitch it more simply as: 'What is the beach made of?'

The project
As a software engineer at the UKHO, my day-to-day job involves solving problems all the time, but I wanted to solve something different to a continuous integration or deployment problem.
After asking around the organisation, I found a problem faced by our Defence team (who are responsible for providing data and products to Defence customers, like the Royal Navy). Our Defence users often require reports on the composition, content and general geography of a beach for exercise planning and execution. Currently we provide information from open source data, such as Open Street Map and ground photography, but this can prove difficult when this data isn't widely available for certain areas. My project looked at how we could fill in these gaps and give our users new information on what a beach may contain.
Getting started
To deal with the lack of data, I first looked at the European Space Agency's Sentinel 2 satellite imagery. This proved too low a resolution (10m per pixel) for the problem, so I was pointed to the Channel Coast Observatory (CCO). The CCO provide coastal aerial imagery of the English coast at 12.5cm per pixel - far better for identifying what a beach is made from.
I then needed to prepare this data for further analysis. To do this, I used Python (with a bunch of geospatial and raster packages) and QGIS. My process is illustrated below:
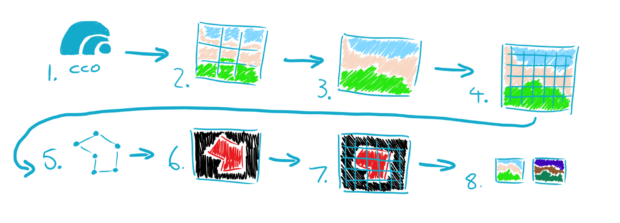
- Visit the CCO website
- Download the sections for the beach of interest
- Merge the cells together into one big image (my main training image was 40,000 x 20,000 pixels)
- Split the image into 256 x 256 pixel cells (required for the model I used - this gave me over 12,000 images)
- Draw spatially referenced vectors around the areas I said were sand
- Rasterize the vectors (turn X+Ys into pixels)
- Split the sand image into 256 x 256 cells
- Normalise my images (just to make the maths a bit quicker)
Using deep learning
Next up came the deep learning. Put simply, this is a machine learning technique that can be used to learn and identify features from data including images, text or sound. So by creating the right deep learning model, we'd be able to quickly identify sand from other geographic features in our aerial image.
The model I made was based on the U-Net architecture. The U-Net had been used previously on a project to identify mangroves from satellite imagery and it worked really well (you can find out more in this post by UKHO data scientist Kari Dempsey).
Broken down, the machine learning process goes like this:
- Make your model
- Feed it a bunch of data
- Feed it even more data
- Get it to classify your data
- Enjoy the pictures it spits out
Whilst this sounds straight forward, it actually involved a lot of picking apart Python code and debugging confusing outputs - which gave me a newfound respect for what data scientists do for a living!
So, did it work?
The proof, they say, is in the pudding:
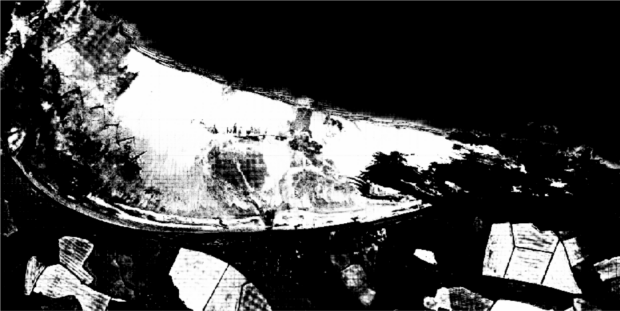

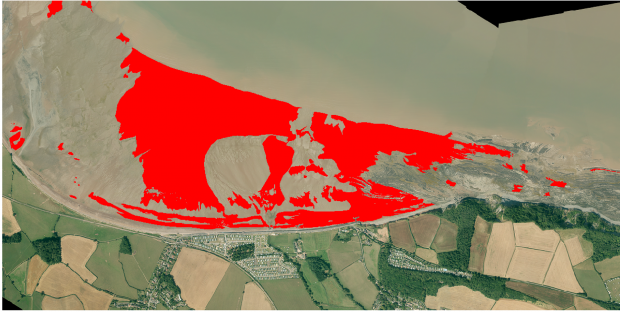
The top image shows what the model classified as sand (shown in white) vs. not sand (shown in black). The bottom image shows my original label of what I determined to be 100% sand overlaid on top.
I was very pleased with the initial results; the model wasn't completely off, and I could understand why it had classified fields as sand (these areas would ideally be masked/removed completely before classifying). I was particularly impressed with the clear definition of sand vs. not sand on the right-hand side, where there is a large rocky outcrop. With a bit more work, this could be a great way of classifying beaches for our defence customers going forward.
Reflecting on the programme
I loved the whole experience of the Data Science Accelerator Programme and learned so much - I wouldn't be able to fit it all into a single blog post. It was nice to jump straight in at the deep-end of deep learning, having already gained the programming knowledge from my day job. Not only did I gain a better idea of what data scientists do day-to-day, but I also gained a bigger appreciation for the brunt work that is data preparation.
My mentors, Alex and Michael, at the Office for National Statistics were incredible and were more than happy to answer the many questions I had - even though I'm sure all the clicking from me drawing vectors was driving them to despair! It was also useful to have UKHO experts on hand - Kari and the Data Science team had plenty of Skype messages from me throughout the 12 weeks, too.
If you're looking for a challenge, I'd wholeheartedly recommend you apply for the Data Science Accelerator Programme. You don't need any prior coding experience, just a drive to learn and improve yourself!
Apply now to take part in the next Data Science Accelerator Programme